我所理解的DDD
DDD是Domain-Driven design的缩写,是软件开发过程中的架构模式。 因为DDD本身有其晦涩的一部分,往往需要通过工程实践才能理解,且也不见得准确。 这篇文章记录的理解也是如此, 其目的是用自己的话术去表述DDD中的一些概念,来给学习DDD的朋友提供一些参考。本文不能代替系统的学习。
什么是Domain Primitive?
等同于Integer, String, Long, Boolean等编程语言的基础数据类型,我们用运算逻辑组合它们以实现具体的业务逻辑。
而这些基础数据类型也同样是对Byte类型的一层封装,并在此基础上提供了各自的类型方法。在英文中叫Primitive data types。
In computer science, primitive data types are a set of basic data types from which all other data types are constructed.[
同理DP(Domain Primitive data types)就是在业务领域,封装Integer,String等基础数据类型而成的领域基础数据。比如用程序领域的Double类型定义金融领域的的Money类型,同时因为Double的值范围远超Money所以需要进行领域范围的限定,比如金额不能为负数。同时这个数值是final的不可变,也就是对应领域概念中的VO(Value Object)。 相比VO, DP可进一步提供领域的方法,比如提供带有货币的输出格式。
public class Money {
final private Double value;
Money(Double value) {
Assert.notNull(value,"Money can't be null");
Assert.isTrue(value>=0,"Money can't be negative")
this.value = value;
}
public String usd() {
return "$" + value; //仅做举例,实现方案不准确
}
}
什么是依赖注入和依赖反转?
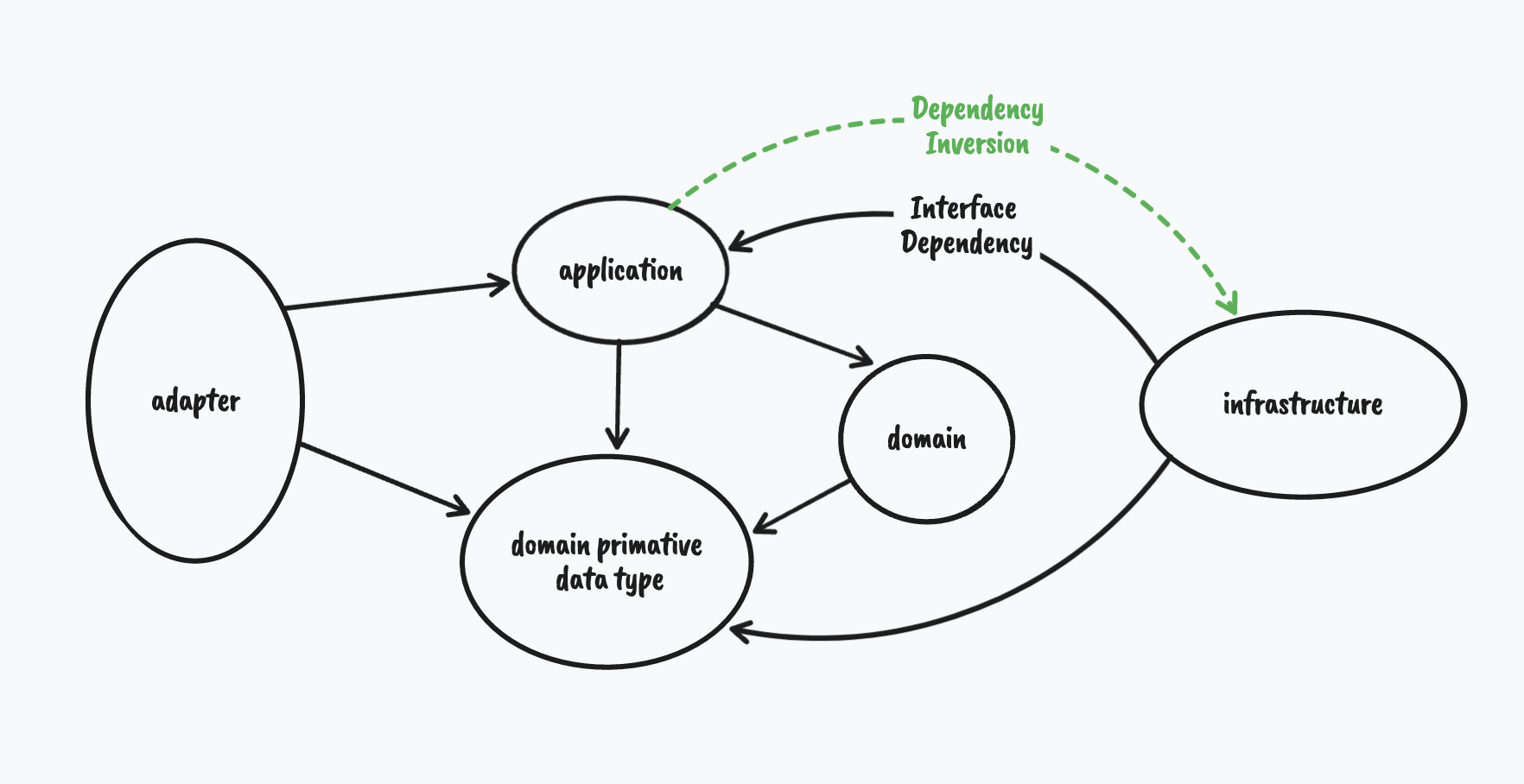
图中展示的是一个DDD项目的模块依赖关系。 黑色实线代表显式的依赖关系,绿色虚线代表通过依赖注入实现的实际的程序执行路径。
Application模块定义领域逻辑的接口。 Infrastructure模块依赖application的接口并负责实现,比如实现了对领域对象的数据存储和获取。 Application并不需要知道具体是用什么方式存储,Redis, MySql甚至文件。 只是在代码执行过程中,依赖infrastructure的实现,这是通过依赖注入实现的依赖反转的效果。
简单来说就是A依赖B的接口,B依赖A的实现,这是通过依赖注入实现的依赖反转。
至于依赖注入的方式,常见有三种构造器注入,接口注入和方法参数注入。具体实现方式不在本文讨论范围。
洋葱架构
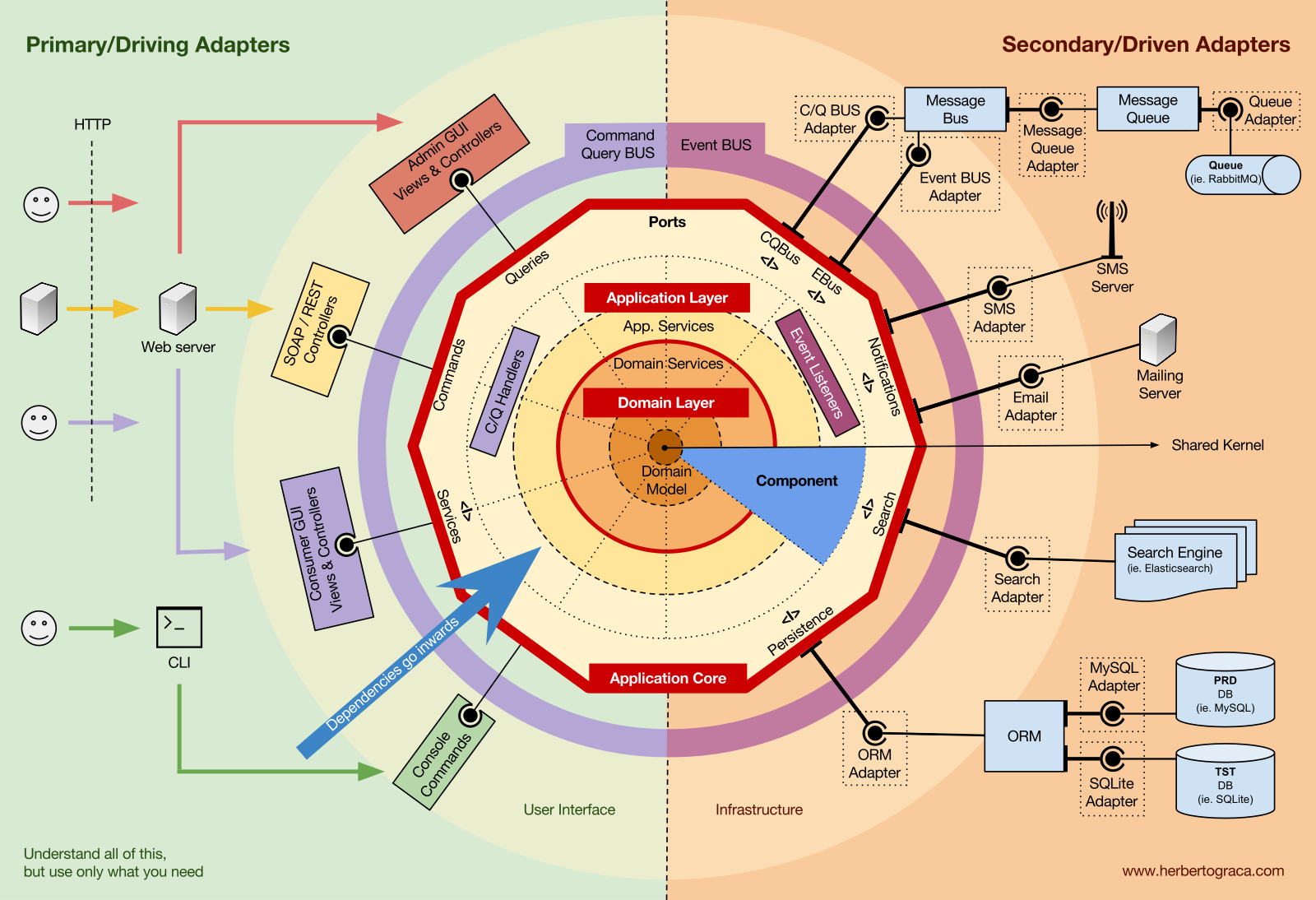
DDD的分层思想,是通过洋葱架构来实现的。即将核心的领域逻辑封装在最内核的区域。保证业务逻辑内部的完整。外层依赖内层的业务定义和实现逻辑,或者内层依赖外层的技术实现。 内层尽可能降低对框架的依赖,对数据库、缓存等基础设施和外部接口的定义抽象SPI。使得每一层完成各自独立的职责,并且可各自独立进行测试。
具体的分层和职责:
- Domain primative data type - 定义领域内数据类型
- Domain - 实现领域业务逻辑
- Application - 实现领域层的编排
- Infrastructure - 基础设施数据库、缓存等的具体实现
- Adapter - 适配层,对外暴露接口Api或者Spi
另外洋葱架构和六边形架构也有一些差别,具体可以参考这篇StackOverflow的回答。
