一款Alfred上的To-do List插件
简介
Alfred被誉为MacOS上的效率神器,关于它的介绍太多了,就不累述。
To-DO List也是众所周之以代办事项形式罗列的清单。也有很多成熟的,需要安装以及付费的软件。而且不一定有相关Alfred快速启动的支持。即使To-do List软件有快捷键支持,可苹果的快捷键在我电脑上,Alfred用到一个,欧路词典占了一个,还有一个留给了输入法,所以到最后很是捉襟见肘。
最基础的Todo-List其实是一个很简单的形式,哪怕用普通的文本就能够实现。Markdown也是支持形如下面格式的渲染:
-[ ] 要做的事情
-[x] 完成的事情
所以为什么不能自己实现一个Alfred插件,来以文本的形式来操作呢?
实现之前当然看看有没有现成的了。很不幸,要么支持不完善,要么只是第三方软件的支持。所以自己来撸一个咯。不过有一篇文章给了最基础的例子Stupid Simple Alfred Todolist – Adam Gray – Medium,证明了这种思路的可行性。实现很简,获取Alfred的参数,然后通过shell文件即可,一行搞定。
echo -e — [] {query}\ >> ~/TODO.txt
路径配置
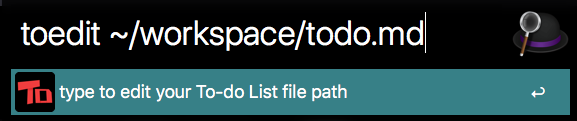
但是遇到一个问题,~/TODO.txt这个地址是写死的,我们需要让用户来配置自己存放文件的位置。
这里用到了sindresorhus/alfy: Create Alfred workflows with ease,一个用Node实现的Alfred脚手架。alfy帮你定义好了输入输出的结构,并且以alfy.input和alfy.output的形式获取和传递就是了,不需要关注底层,非常友好。同时结合alfy提供了设置cache方法,实现一个Alfred的toedit命令,只需要一行代码就可以完成,设置工作。
alfy.cache.set('path',alfy.input);
写入
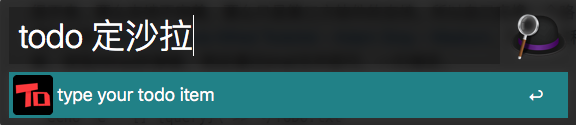
写入就是用将输入的内容,用js的fs模块,写入到之前设置的路径,path获取方式与之前设置时的key对应。
var filename = alfy.cache.get('path');
fs.appendFileSync(filename, "- [] "+alfy.input+"\n")
勾选
写入完成后,我们需要在一项任务要去勾掉它,这也是To-do List最有成就的一步。怎么能没有呢?功能的实现思路也简单:
- 读取To-do List文件。
- 根据参数匹配到对应的且未完成的行。
- 将未完成
- [ ]标记替换为- [x]已完成标记。 - 将文件重新写入
所以流程一致,获取路径,配合fs模块读写,剩下大部分就是js的逻辑代码,与平台无关了。
fs.readFile(filename, function(err, data) {
var array = data.toString().split("\n");
const results = array.filter(word => (word.toString().indexOf(alfy.input) > -1 && word.toString().indexOf('x') === -1))
.map(x => ({title: x,arg:x}));
alfy.output(results);
});
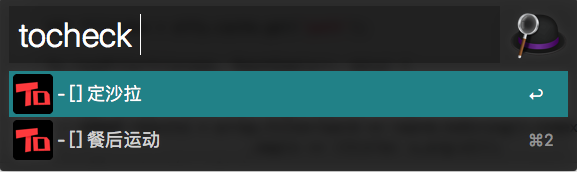
实现效果如图,没有参数的时候,会过滤出所有未勾选的选项。
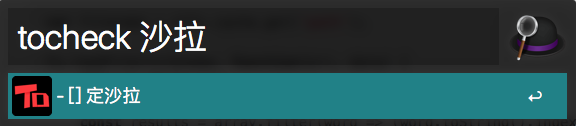
当有参数时,就快速查找到需要的,然后选择想要的回车,既可以做出更改。
结合MarkEditor
因为Markdown默认支持To-do List格式的渲染,而且我之前发现的一款MarkEditor的Markdown软件,既可以支持菜单栏书写,同时能够直接点击-[ ]和-[x]标签进行选择和反选。非常人性化。
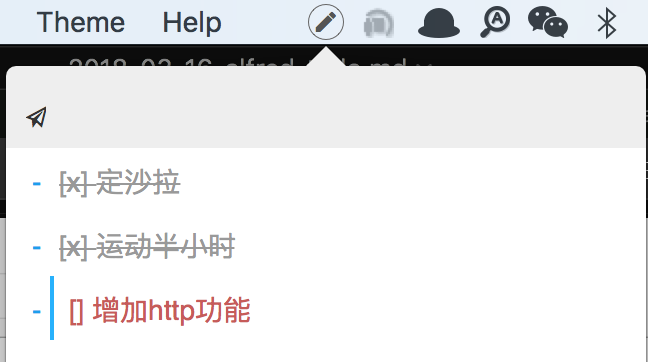
这样一个能用的Alfred To-do List workflow就完成了。
安装
目前已经把初版发布到了npm上面,可以一行命令来安装。装好了别忘了先用toedit指定一个用来存储To-do List的文件路径。
npm install --global alfred-todo-list
同时源码也放到Github上了,便于后续维护drinking/alfred-todo: A to-do list workflow for Alfred。
其他可以改进之处
- 增加时间选项,根据预设时间,触发提醒。
- 当前只是简单粗暴地针对整个文件读取和写入,当数据量大时,还是有通过数据流方式读取和输出的余地。
- 去重复
总结
好像一不小心安利了不少app,大家可以自由选择。每个人用趁手的就好。Alfred已经是我工作中不可或缺的一部分,而且越来越喜欢集成不同的功能进来。现在还有个方向是信息获取这块,有人做过通过Alred获取知乎,豆瓣或者股票的消息。如果没有,比如我想获取某直播吧数据,完全可以自己来实现,针对不友好的HTML格式文本就可能中间需要自己解析一下了。
